
Part 3 Frequency and Time-Frequency Domains Analyses | Analyzing Neural Time Series Data
Chapter 10&11
推荐3b1b的一段关于卷积、离散傅里叶变换(DFT)和快速傅里叶变换(FFT)的视频
Supplementary Code for Figure 11.5
对于书中所提供的图11.5对应代码的一些细节注释
%% Figure 11.5 |
The Fast Fourier Transform | FFT
如何将 fft 函数的输出与实际的频率和幅值对应起来:
- 采样率:$F_s$ 采样点数:$N$
- FFT后向量中某点索引:$n$
- 该点频率:$f_n=(n-1)\cdot F_s/N$
- 该点幅值:$abs(Result_{FFT})/(N/2)$
Chapter 12
How to Wake Wavelets | 小波的创造
不同于使用傅里叶变换进行的分析,使用小波变换时小波的频率和数目可以自行选择。一组具有相同性质但频率不同的小波叫作小波族,构造一组小波族有如下限制:
- 不能用比你划分的时间小段(epochs)更慢的频率。例如,你有一段1s长的数据,那么你不能分析低于1Hz的活动,应该让这1s中包含多个活动周期,建议使用4Hz或更快的小波。
小波的频率不能高于奈奎斯特频率(采样率的一半)
选择相近的频率所获得的结果会很相近(例如15.0Hz和14.9Hz),且越密集的频率所需要的计算时间会越长,一般而言,在3Hz到60Hz之间选择15到30个频率就够了。
Chapter 13 Complex Morlet Wavelets (cmw)
Create complex sine wave
复数域的Wavelet函数也是由sine函数和Gaussian相乘得来,只是所使用的sine函数是在复数域表示的()
- (the x-axis offset for Gaussian are omitted)
The Result of cmw
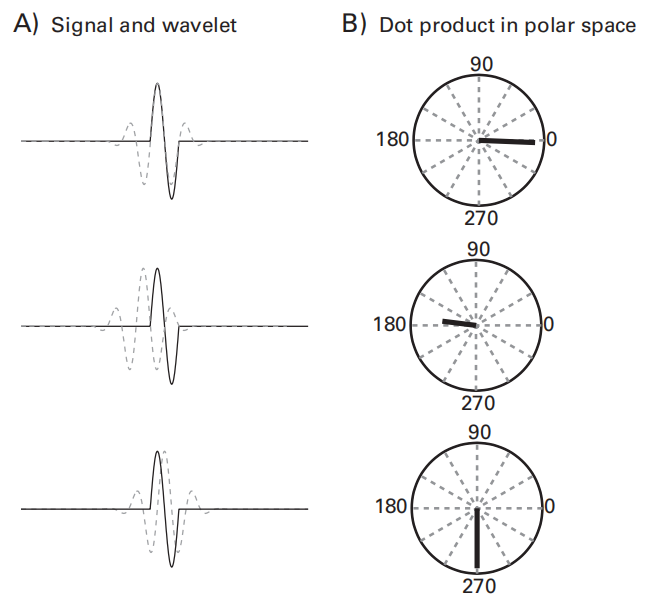
复数wavelet与信号点积的结果有三个维度:时间、实部、虚部。将该结果绘制在复平面上,其在实轴、虚轴上的投影分别对应于wavelet的实部、虚部与信号的点积结果。
点积结果在复平面上所对应向量的长度反映了信号(signal)和核(kernal)的相似(重叠)程度,而且该长度与二者间的相位关系无关。相位关系由向量与实轴的夹角表示。
- 在实轴上的投影:带通滤波信号,其正负符号反映相位关系
- 向量长度(振幅):反映wavelet与signal的相似性或重叠度,其平方称为功率
abs(X).^2;orX.*conj(X);(乘以共轭)
- 与实轴夹角:反映了在wavelet中心时间点(即分析时段的中间时刻)和wavelet的主频率(即小波的主要振荡频率)下,信号的相位信息。
angle(X);
- 上述提到的功率和相位值只能作为估计值,因为它们会受到邻近时间点活动的影响。
Parameters of Wavelets
最低频率
- 如果关注alpha-band activity,大概在5或6Hz即可
- 划分的时间区段(epoch)尽可能包含多个周期(如果epoch长1s,则不要低于4Hz)
最高频率
- 不能超过奈奎斯特频率(采样率的一半)
- 单个wavelet周期尽可能包含更多的信号数据点,可以提高信噪比
- 没有特别的期望的话,可能选择4Hz到6Hz的频率范围
频率数目
- 一般取20-30个频率足够覆盖较宽的频率范围。条件允许的情况下当然是越多越好,但是相近的频率不一定能提供更多信息。
频率分布间隔
线性分布
突出频谱的高频段
可以直接使用
imagesc(EEG.times,frequencies,tf_data);绘图imagesc(EEG.times,frex,eegpower)
set(gca,'clim',[-3 3],'xlim',[-200 1000],'ydir','norm')
title('WRONG Y-AXIS LABELS!!!!')
ylabel('Frequency (Hz)'), xlabel('Time (ms)')
对数分布(推荐):
4-8Hz(theta)和30-80Hz(lower gamma)在y轴上占据的宽度会比较接近
突出频谱的低频段
使用
imagesc(EEG.times,[],tf_data)绘图imagesc(EEG.times,[],eegpower)
set(gca,'clim',[-3 3],'xlim',[-200 1000],'ydir','norm')
set(gca,'ytick',1:6:num_frex,'yticklabel',round(logspace(log10(min_freq),log10(max_freq),6)*10)/10) % important!
title('CORRECT Y-AXIS LABELS!!!!')
xlabel('Time (ms)')
wavelets 的长度
- 要足够长,使得两侧能衰减到0(接近0)
- 没有长度限制,如果 -1s ~ +1s 不够,就设置成 -2s ~ +2s,不同的频率长度也不一定要相同
- wavelet 的图像要设置在时间轴中央(关于中间时刻对称),最简单的方法是将时间范围设置成 -x seconds to +x seconds
- wavelet 的采样率要和 EEG.data 一致
Gaussian函数要包含多少个周期
- “包含的周期数目”指的是Gaussian函数标准差公式中的
- 包含周期数越多,频率精度越高,时间精度越低
- 包含周期的数目也可随频率改变
- 应至少包含3个周期,至多包含14个周期
- 在wavelet的非零段,需要保证数据(进行卷积的信号片段)的平稳性(均值、方差等统计特性保持稳定)
相邻频率对小波卷积的贡献程度
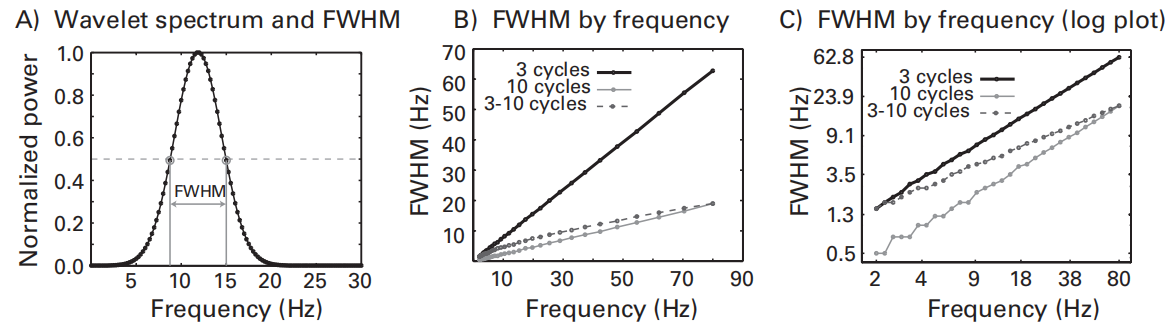
Full width at half-maximum (FWHM)
指频谱上功率在峰值的左右两侧分别为50%时的频率宽度:,其中是频率响应的标准差
- 首先标准化功率谱,使得峰值为1,两端衰减至0
- 找到功率值为0.5的点对应的频率,即可计算出FWHM
卷积的Matlab计算技巧
- FFT的数据点数为时,计算速度更快。可以通过适当的补零来实现
- 不需要对每个trial进行一次卷积,可以将所有trial连接成一个长时间序列,再对整个时间序列执行一次卷积
Chapter 14 Bandpass Filtering and the Hilbert Transform
The Procedure of Hilbert Transform | Hilbert变换及其步骤
对于一个只有实部的信号,我们无法获得其相位信息,Hilbert变换能够帮助我们从实信号中提取出虚部,从而获得相位信息
正频率与负频率
正频率:介于0与奈奎斯特频率之间的频率(不包含0和奈奎斯特频率)
负频率:大于奈奎斯特频率
为什么要区分正频率与负频率?
信号的实部与虚部:一个纯实信号(如 )在频域中有对称的正负频率分量,它们共同构成了这个信号的傅里叶表示。然而,虚部(如)的引入使得信号不再是对称的,因此需要对正频率和负频率分量分别进行处理,以生成一个复信号。
Hilbert变换的步骤:
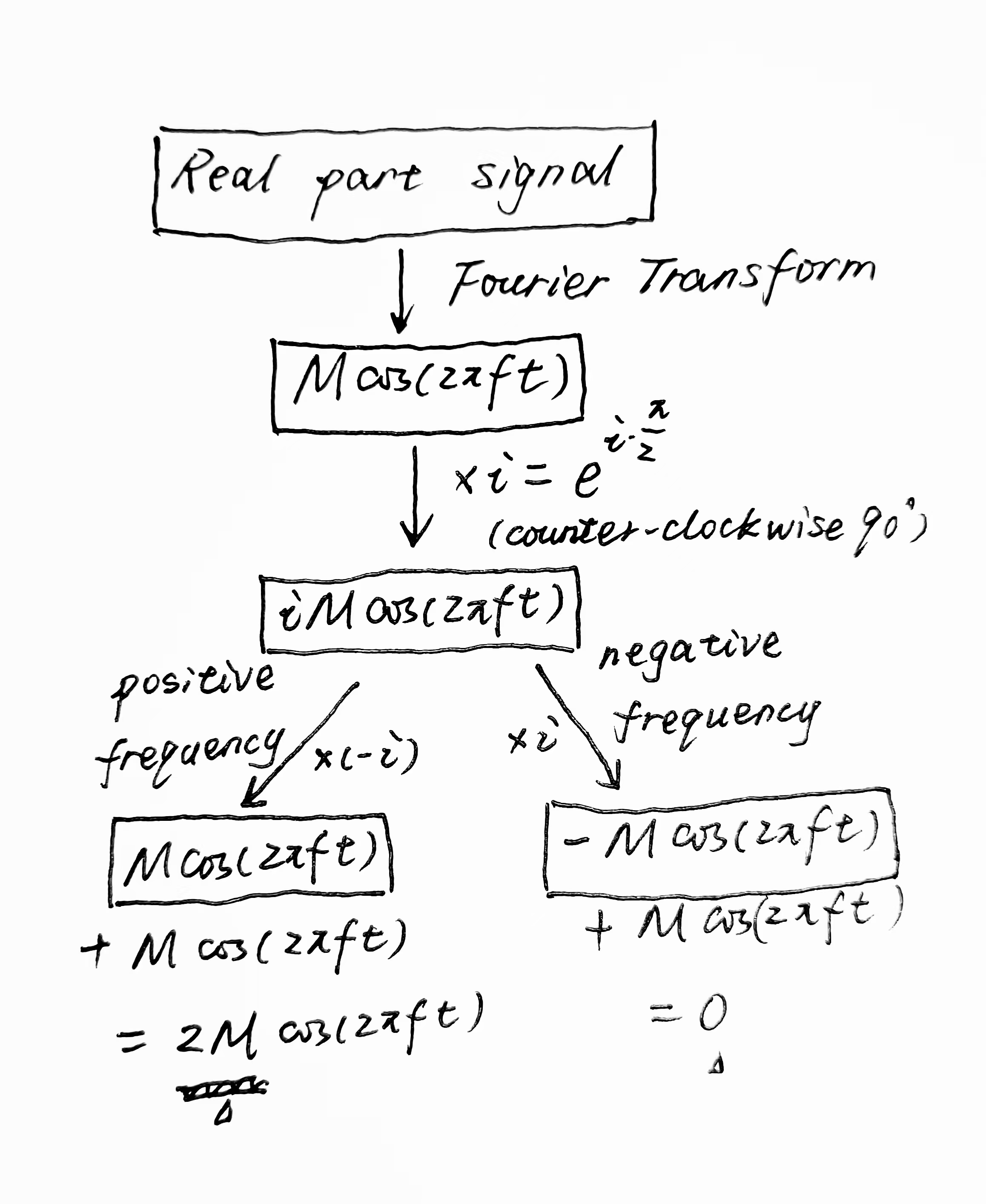
对信号做Fourier变换,得到,乘以复数单位 ,得到
正负频率的处理
正频率的处理
- 逆时针旋转四分之一周期:正频率分量的傅里叶系数在复平面上表示时,通过逆时针旋转四分之一周期(即或),可以将余弦信号()转化为正弦信号()。
- 数学处理:这种旋转通过将傅里叶系数乘以 (即$-i=e^{-i\pi/2}$)来实现。这样,当你把旋转后的正频率系数加回到原来的正频率系数时,实际操作效果是将这些系数变成了原来系数的两倍。
负频率的处理
- 顺时针旋转四分之一周期:负频率分量对应的傅里叶系数需要顺时针旋转四分之一周期(即$90°$或$\frac{\pi}{2}$),将余弦信号($\cos (2πft)$)转化为负的正弦信号。
- 数学处理:这个旋转通过将负频率傅里叶系数乘以 (即 )来实现。由于这导致$i$和$i$相乘等于-1,负频率的系数经过处理后在添加回原来的系数时会变成零。这意味着负频率部分被完全消除。
- Hilbert变换的代码
%% the FFT-based hilbert transform |
- Hilbert变换并不改变信号的实部,可用此性质检验变换后的信号是否正确
- 在Matlab中,函数
hilbert()的输入可以是一个矩阵filtered_data = zeros(demension_1,demension_2),但是矩阵的第一个维度必须是时间(filtered_data = zeros(EEG.pnts,EEG.nbchan)),即对于二维矩阵,矩阵的每一列是一组信号 - 在进行Hilbert变换前,建议先对信号进行滤波,从而将信号分离成不同的频段,以便于分析
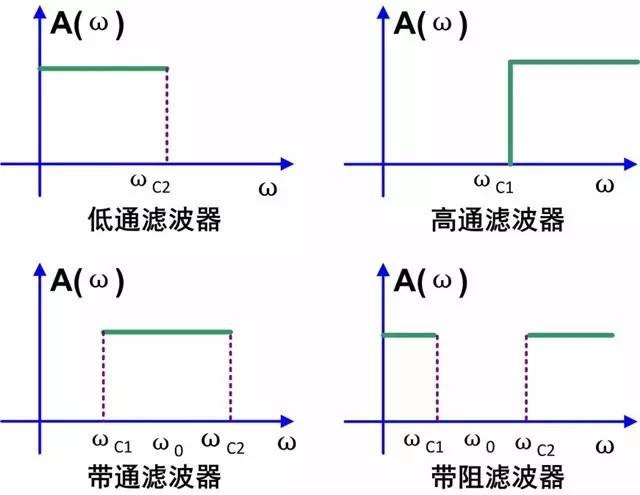
Bandpass Filtering | 带通滤波
FIR & IIR Filters
- FIR (Finit Impluse Response, 有限冲激响应):提供脉冲输入后,响应会在某一点终止。更稳定,且不容易引入非线性相位畸变
- FIR (Infinit Impluse Response, 无限冲激响应):提供脉冲输入后,响应不会终止。算法计算复杂度更低,耗时少
Bandpass, Band-Stop, High-Pass, Low-Pass
Create a filter kernel in Matlab
firls():通过最小二乘创建FIR滤波器。常用于宽频带第一个参数:The order of the filter,定义kernel的长度(单位为ms),决定了滤波器频率响应的精度。通常设置为下频界的2~5倍(如果下频界为10Hz(100ms),那么就是200到500ms)
第二个参数:一个包含一组频率的频率向量,决定滤波器频率响应的形状。对于带通滤波器,可以使用六个频率:①零频率,②下过渡区开始的频率,③带通的下界,④带通的上界,⑤上过渡区结束的频率,⑥奈奎斯特频率。最后将这6个频率除以奈奎斯特频率(即以奈奎斯特频率为1)
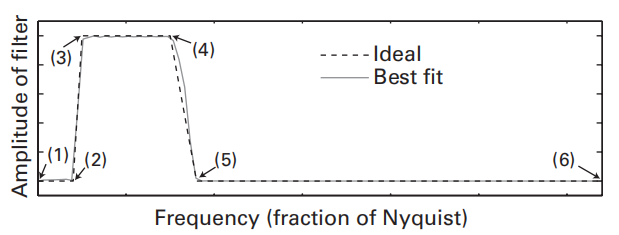
- 第三个参数:一个元素为0~1的向量,通过控制第二个输入参数的纵坐标来修改滤波器频响形状。对于带通滤波器,可以使用[0 0 1 1 0 0],其中的“1”对应带通平台的上下频界,第一个和最后一个“0”对应直流和奈奎斯特频率,第二个和第五个“0”对应过渡区的频率界。
fir1():带有紧密过渡区的窗函数线性相位滤波器。常用于窄频带- 第二个参数只需输入带通下界、带通上界两个频率值
fir2():基于频率采样的滤波器结构firrcos():凸起的余弦形滤波器gaussfir():高斯形滤波器firpm():Parks-McClellan
频域内的尖锐边缘会引起时域内的伪影振荡,使用包含过渡区的滤波器可以缓解这一点,但是会牺牲一定的频率精度
检验滤波器是否合格:$sse=\Sigma_{i=1}^{n}(ideal_i-actual_i)^2$,sse即the sum of squared errors,对理想滤波器而言,n指的是滤波器的6个定位点(第二个参数)。
得到kernel后,使用
filtfilt()函数完成对信号的滤波,该函数输入的第一个为kernel;第二个参数为一个标量和向量,代表kernel的权重。通常设为;第三个参数为被处理信号。- 使用
filter()函数会引入相位延迟,而filtfilt()通过两次应用filter函数来消除相位延迟。具体来说,它首先对信号进行正向滤波,然后反转信号顺序,再次应用相同的滤波器,最后再将信号反转回来。
- 使用
Butterworth (IIR) Filter
% 5th-order butterworth filter
[butterB,butterA] = butter(5,[(center_freq-filter_frequency_spread)/nyquist (center_freq+filter_frequency_spread)/nyquist],'bandpass');
butter_filter = filtfilt(butterB,butterA,data2filter);
Chapter 15 Short-Time FFT
Short-Time FFT 即取一小段时间内的数据进行fft,为了减小artifact,需要对这一段数据的两侧进行减弱处理
可以用Hann、Hamming、Gaussian三种函数(tapers)完成减弱处理,推荐用Hann,因为它最终会衰减到0。其他taper还包括Kaiser, cosine, Blackman, …
timewin = 400; % in ms, for stFFT
timewinidx = round(timewin/(1000/EEG.srate));
% create hamming
hamming_win = .54 - .46*cos(2*pi*(0:timewinidx-1)/(timewinidx-1));
% create hann
hann_win = .5*(1-cos(2*pi*(0:timewinidx-1)/(timewinidx-1)));
% create gaussian
gaus_win = exp(-.5*(2.5*(-timewinidx/2:timewinidx/2-1)/(timewinidx/2)).^2);得到FFT结果后,建议以目标频率周围几个频率的频响平均值(或Gaussian加权平均值)作为最终结果,可以提高信噪比
时间段长度的选择
- A trade-off between temporal and frequency precision and resolution
- 时间段长度应至少包含所分析频率的一个周期
- 时间段长度可以设为频率的函数(低频-时间段长;高频-时间段短)
Chapter 16 Multitapers
常用于低信噪比的情况,如高频活动或功率的单试次估计
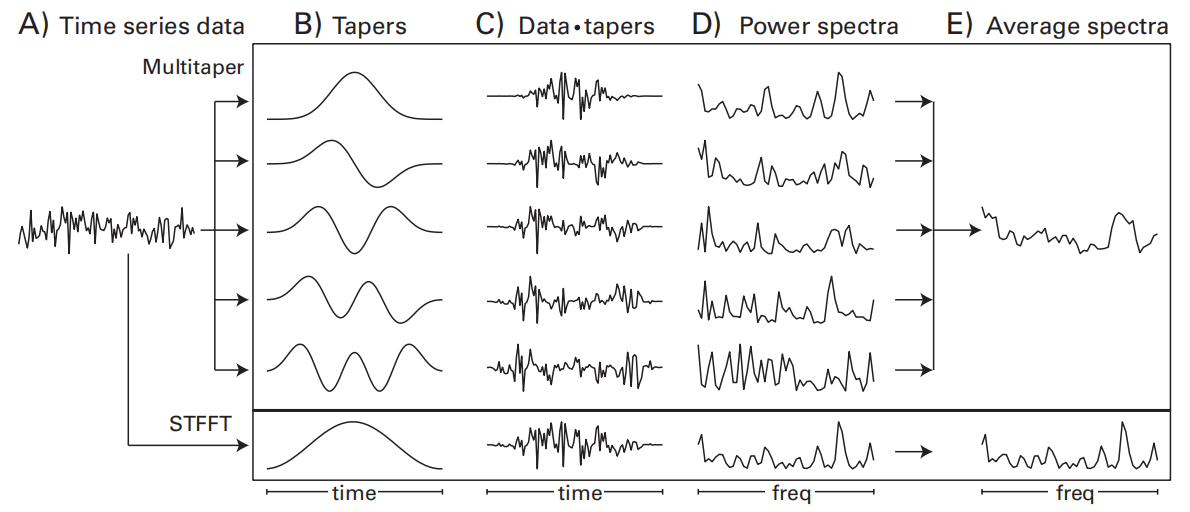
The Tapers
multitapers使用的tapers是discrete prolate spheroidal sequences,也叫做Slepian tapers。可以使用Matlab中的
dpss()函数生成。一组slepian tapers相互正交dpss函数的基本调用格式如下:[tapers, eigenvalues] = dpss(N, NW);
N:时间段的长度(以样本点为单位)。NW:时间带宽参数。它是时间段长度和频带宽度的乘积,NW = N * (W / (Fs/2)),其中W是频带宽度(以采样率的一半为单位,所以要除以采样率的一半),Fs是采样率。tapers:返回的锥窗函数的矩阵,每一列是一个taper。eigenvalues:对应的特征值,表示每个taper在指定频带内包含的能量。
确定参数
- 时间段长度
N:取决于你想要的时间分辨率。 - 带宽参数
NW:它控制频谱的平滑程度。NW的值越大,频谱越平滑,但时间分辨率越低。通常,NW的值在 2 到 4 之间,也可随频率值改变。
N = 1000; % 假设有1000个样本点
W = 2; % 频带宽度, 以赫兹为单位
Fs = 1000; % 采样率
% 计算NW参数
NW = N * (W / (Fs/2));
[tapers, eigenvalues] = dpss(N, NW);确定锥窗数量
dpss函数返回的锥窗数量是2*NW四舍五入后的整数。numTapers = round(2 * NW);
分析特征值
tapers的最后一个特征值一般较低(例如 0.7 或 0.8),表示该taper的频谱表现较差,通常可以忽略这些较差的锥窗。% 检查特征值
disp(eigenvalues);
% 忽略最后一个特征值较低的taper
tapersToUse = tapers(:, eigenvalues > 0.9);5. 完整示例代码
% 参数设置
N = 1000; % 样本点数
W = 2; % 频带宽度
Fs = 1000; % 采样率
NW = N * (W / (Fs/2));
% 生成tapers
[tapers, eigenvalues] = dpss(N, NW);
% 显示特征值
disp(eigenvalues);
% 选择特征值大于0.9的tapers
tapersToUse = tapers(:, eigenvalues > 0.9);
% 绘制tapers
figure;
plot(tapersToUse);
title('Selected DPSS Tapers');
xlabel('Time (samples)');
ylabel('Amplitude');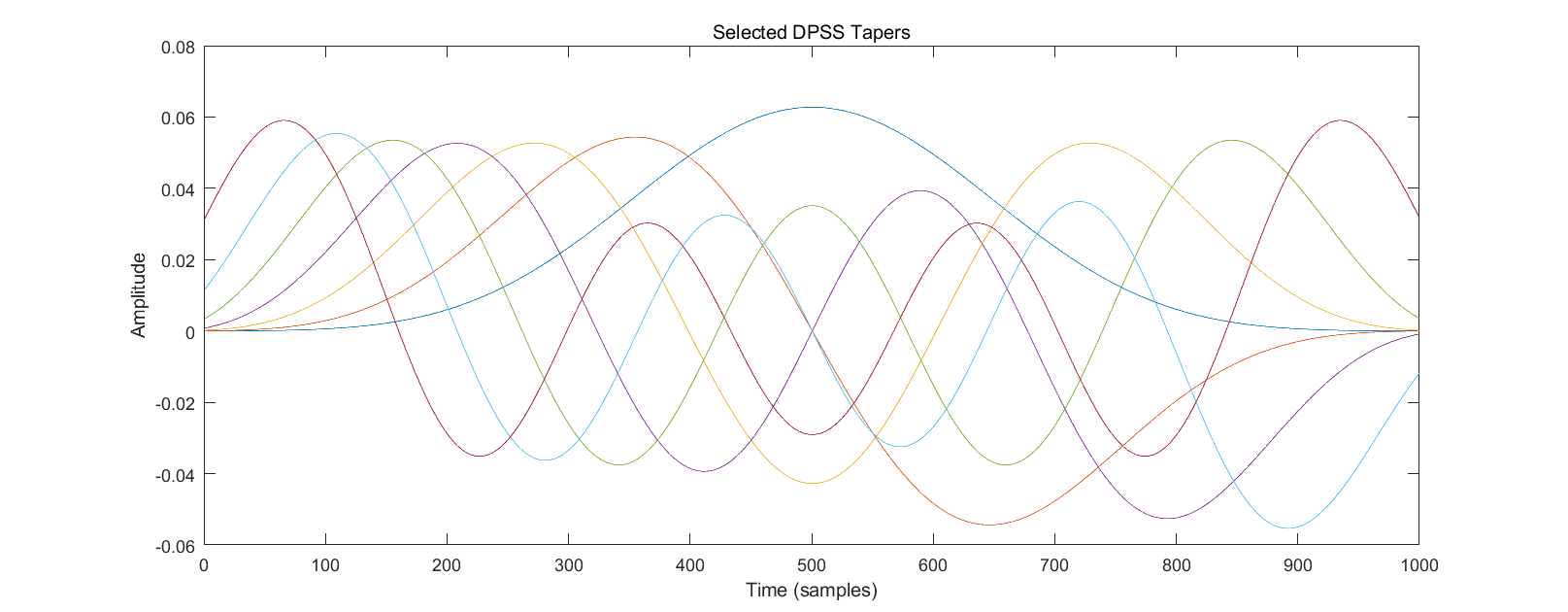
通过使用多个taper,multitaper方法在频率轴上引入了一定的平滑效应。这种平滑可以减少频率分辨率的精细度,使得频谱变得更加连续和平滑。
(ChatGPT的例子)假设你在一个任务中研究Gamma频段活动,并且发现某些被试的伽马频段峰值在50Hz,而另一些被试的峰值在65Hz。如果你使用精细的小波分析,每个被试的频谱可能显示出各自独特的伽马活动峰值,但这些峰值的差异可能在跨被试平均时抵消,导致难以在群体水平上识别伽马活动。此时,通过使用multitapers方法并引入适当的频率平滑,你可以让50Hz和65Hz的峰值在频谱中更接近,从而在群体平均时更容易识别出Gamma频段的整体活动。这种平滑可以帮助你在不损失重要频率信息的情况下,更好地捕捉和解释群体层面的神经活动。
适用情况
- noisy data, small number of trials
- single-trial analyses, analyze frequencies above around 30 Hz
- high-frequency power above around 60 Hz
Chapter 18 Time-Frequency Power and Baseline Normalization
1/f Power Scaling
- EEG的时频功率和频率呈现幂函数的关系:$power=\frac{c}{frequency^x}$,难以进行数据分析
Baseline
- baseline指的是一段时间,通常在试验开始前几百毫秒,在这段时间内很少或没有任务相关的脑电活动。
Decibel Conversion
- 计算公式:
由于对数函数的存在,该公式不适用于存在非正值的数据,但功率值总是为正的。
- Matlab计算代码
% 定义baseline所处时间段 |
- 一些细节
- 对于多个trial平均后的数据,经分贝转换后的功率通常分布在$\pm 1-4\ dB$
- 通常采用对称的颜色映射分布,便于比较增大与减小的幅度。某些情况下也可以用不对称的分布来突出某些特征
Percentage Change
- 计算公式
Baseline Division
- 计算公式
Z-Transform
- 计算公式其中n是baseline中的时间点数目,分母是baseline的标准差。当baseline的标准差较大时,不建议使用Z-Tranform
均值or中位数
- 在trial数量少、噪声大的情况下,中位数更不易受到离群值的影响
- 在对所有trial进行平均前,先对单个trial进行baseline normalization(single-trial Z-transform),可以减少离群数据的影响
如何选择Baseline
- ERP
- baseline通常终止于time=0
- time-frequency analyses
- baseline通常设置为 -500 ~ -200 ms 或 -400 ~ -100 ms。因为在提取频域信息时,每个时间点上的数据会“泄露”到周围的时间点上,所以应该尽量避开刺激前的一段时间
- 要确保选择的baseline时间段内没有多余的刺激,比如试验开始的提示等
- 尽可能使用pretrial period作为baseline,而非preresponse period等其他时间段,以减少刺激相关神经活动的影响
- baseline通常包含几百毫秒
- 如果无法使用pretrial period作为baseline,可以考虑如下替代方案
- 使用休息时间作为baseline。但被试对待休息与试验时心态的差异可能会影响最终结果
- 使用对照条件(区别于实验条件)作为baseline。对照与实验条件下反应时间的差异可能会影响最终结果
- 使用整个实验过程作为baseline。难以观测到功率在整个实验中的持续变化
- 如果有多种不同的试验条件(condition),需要考虑使用 condition-specific baseline 还是 condition-average baseline ,即不同条件是否要使用同一段baseline
Signal-to-Noise Ratio (SNR) Estimates| 信噪比的估计
信噪比:可以认为是信号的平均值与信号的标准差的比值
计算公式:
对ERP而言
- $\mu$可以认为是某个ERP成分的峰值,$\sigma$可以认为是baseline的时间方差
- 对time-frequency analyses
- $SNR_{tf}$:$\mu$为所有trial的平均功率,$\sigma$为所有trial的功率标准差,$tf$表示一个时频点
- $SNR_{base}$:$\mu$为所有trial的平均功率,$\sigma$为baseline的功率标准差
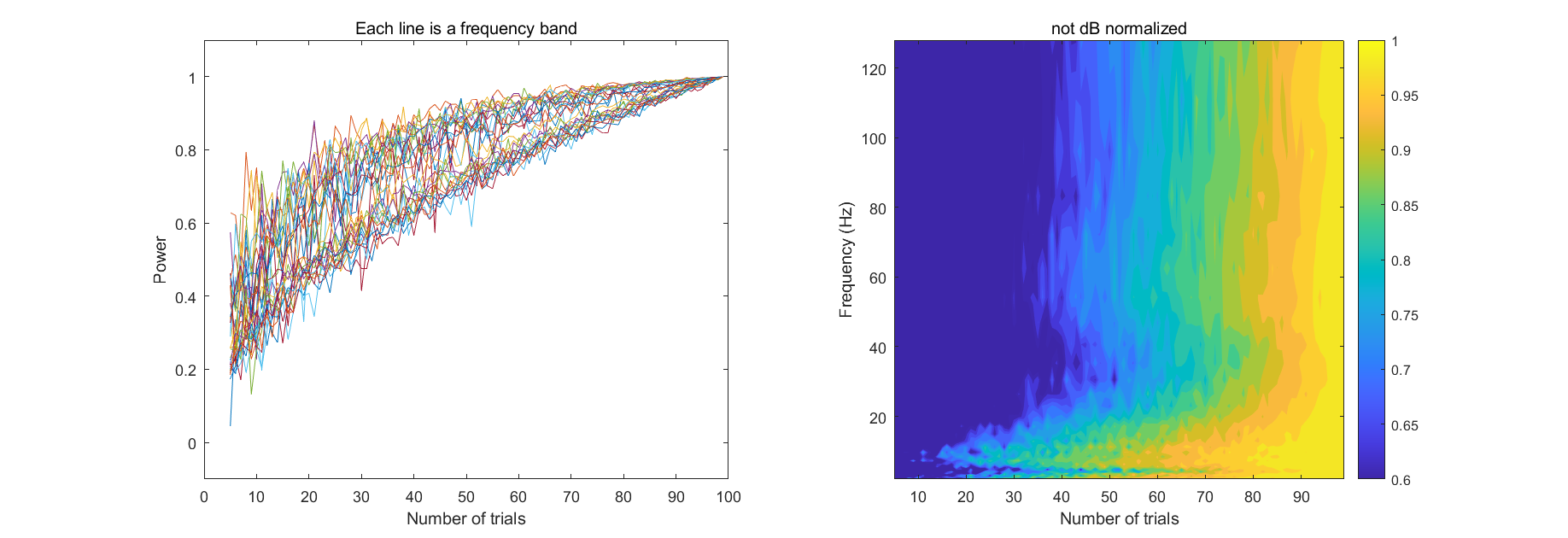
检验Trial的数量是否足够
随机选取n个trial,计算这n个trial的平均值与所有trial平均值的相关系数,相关性越强,说明trial的数目越充足。对于没有进行baseline transform的非正态分布数据,通常计算Spearman相关系数
DownSampling | 降采样
时频分解后由于泄露,信号的时间精度会降低,因此时间分辨率可以适当降低,比如降低到 40 或 50 Hz
Chapter 19 Intertrial Phase Clustering
Intertrial Phase Clustering (ITPC)
主要思路:将不同trial在某一时刻的相位向量绘制在复平面上,模长为1,角度为各相位值,再计算所有向量的平均值,所得新向量的平均长度介于0和1之间,反映了多个Trial间相位的一致性(ITPC),新向量的相位角则反映了相位的平均大小
计算公式:
Trial数目越多,ITPC值减小并趋于稳定。所以尽量保证Trial数目足够多,且不同实验条件下的Trial数尽量保持一致
Trial数目不足且不一致时可采用的措施
对trial进行筛选,以匹配不同条件下的trial数目
采用baseline ITPC,因为不服从1/f的分布,通常采用linear baseline
将$ITPC$转换为$ITPC_Z$
Effect of Temporal Jitter on ITPC
- Temporal Jitter:刺激呈现等事件发生时间的波动或不确定性
- Temporal Jitter对相位的影响大于对功率的影响,且在高频处的影响更大
ITPC and Power
- ITPC和Power通常是不相关的,可以分别进行分析说明
- 功率越小,相位越难估计(可以想象功率为0的极端情况)
Weighted ITPC (wITPC)
- wITPC中向量的长度不是1,而是和试验中的行为或试验变量有关,比如反应时间、刺激亮度、瞳孔反映等
wITPCz(待补充)
Chapter 20 Differences among Total, Phase-Locked, and Non-Phase-Locked Power and Intertrial Phase Consistency
Non-Phase-Locked Power (Induced Power)
- 计算方法:首先从每次试验的数据中减去ERP,然后对单次试验进行时间-频率分解,计算功率。这种方法去除了所有相位锁定 的成分,因此剩下的功率仅代表非相位锁定的部分
Phase-Locked Power
- 计算方法:从总功率中减去非相位锁定功率,注意需要先将总功率和非锁相功率分别转化为分贝,再相减
- 高频活动在多个周期后难以保持相位锁定,因此相位锁定功率中通常不包含大于20Hz左右的高频成分
- ERP Time-Frequency Power
- 先计算ERP,再进行频域变换,而不是先进行频域变换,再计算ERP
- It is appropriate to use the ERP baseline to normalize the ERP time-frequency power, rather than using the base line period power from the total or non-phase-locked analysis.
